728x90
필수 라이브러리
| 이름 | |
| 판다스(Pandas) | 데이터를 수집하고 정리하는데 최적화된 도구 Series(1차원)와 DataFrame(2차원) 제공 |
| 넘파이(Numpy) | |
| 맷플롯립(Matplotlib) | |
| 사이킷런(sckit-learn) | |
| 사이파이(Scipy) |
시리즈
- 데이터가 순차적으로 나열된 1차열 배열
- 딕셔너리{키: 값}와 비슷한 구조
# 시리즈 만들기 기본구조
pandas.Series(딕셔너리)
pandas.Series(리스트)# 딕셔너리를 시리즈로 변환하기
# 판다스 import 하기
import pandas as pd
# 딕셔너리 생성
dict1 = {'a':1, 'b':2, 'c':3}
# 시리즈 변환
sr = pd.Series(dict1)
# 출력
print(type(sr))
print(sr)
# 리스트를 시리즈로 변환하기
# 판다스 import 하기
import pandas as pd
# 리스트 생성
list1 = ['a', 'b', '1', '2', '2023-01-01']
# 시리즈 변환
sr = pd.Series(list1)
# 출력
print(type(sr))
print(sr)
# 인덱스, 데이터 값 분리
index = sr.index
values = sr.values
print(index)
print(values)
# 인덱스 이름 설정
tup_data = ('a', 'b', '1', '2', '2023-01-01')
sr2 = pd.Series(tup_data, index=['에이', '비', '일', '이','새해'])
sr2
# 원소 선택해서 추출하기
sr2['에이']sr2[0]
# 여러개 추출 시 대괄호 필요
sr2[['에이', '비']]sr2[[0, 1]]#범위로 출력
sr2[0:2]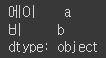
데이터 프레임
2차원 배열
여러개의 열벡터들이 같은 행 인덱스를 기준으로 줄지어 결합된 2차원 벡터 또는 행렬(matrix)
# 데이터 프레임 만들기 기본 구조
pandas.DataFrame(딕셔너리 객체)
pandas.DataFrame(2차원 배열, index=행 인덱스 배열, columns=열 이름 배열)
728x90