1. 가상화 및 클라우드 개요
기존 환경의 문제점들
대부분 IT 에너지는 Infrastructure 유지와 Application 유지에 사용된다.
| 원인 | 극도의 복잡성 빈약한 인프라에 의존 |
| 결과 | 70% 이상의 IT 예산이 현상유지에 사용 30% 이하의 IT 예산만이 개선과 경쟁력 강화를 위해 사용 |
-> IT 경쟁력이 곧 사업 경쟁력
가상화 기술을 통해 해결
모든 자산의 가상화
가상화 플랫폼을 이용하고 동적이고 유연한 업무 인프라를 구축
데이터센터의 모든 리소스를 가상화
가상화 유형
| 서버 가상화 | 네트워크 가상화 | 스토리지 가상화 | 데스크톱 가상 |
가상화 도입 효과
서비스를 위한 물리적인 서버의 대수를 감소
전체적인 상면/전력/관리 비용을 절감
그린 IT구현을 위한 탄소배출 절감
| 효과 | 예시 |
| 서버 통합 | n대의 서버를 2 Way 3대로 자원관리 향상(CPU, 메모리, 스토리지) |
| 그린 IT | 탄소 배출량 감소 |
| 유지보수 비용 절감 | H/W 유지보수비용 절감(인적 자원, 전기, 에어컨 등등) |
| 상면 공간 절감 | 시스템렉 n개 -> 1개로 운영 |
*추가 자료: 자원 관리 항목 https://m.blog.naver.com/PostView.naverisHttpsRedirect=true&blogId=cmtes_inc&logNo=221628997448
정보시스템 운영 상태관리 (서버 cpu, memory, disk 등의 관리) 방법은 ?
정보시스템 운영상태 관리란 ? 정의 : 정보 시스템(서버시스템 정도)을 구성하는 시스템 구성 요소에 대한 ...
blog.naver.com
가상화 정의
가상화는 운영 체제에서 물리적 하드웨어를 분리하여 IT 담당자가 직면한 많은 문제에 대한 해결책을 제공하는 기술
가상화의 발전
| Gen 1 | Gen 2 | Gen 3 | Gen 4 |
| 클라이언트 하이파바이저 (hosted hypervisor) |
서버 하이퍼바이저 (Bare-Metal) |
가상 인프라 | 클라우드 |
| 높은 이용율 일부 OS/App Fault Isolation |
전체 OS/App Fault Isolation 가상 머신들의 캡슐화 H/W Independence |
중앙 집중화 관리 운영중 가상 머신의 이동 자동화된 비즈니스 연속성 |
Computer, Network, Storage 자원들에 대한 정책 기반 제어 보안과 장애 대응(Fault Tolerance) 어플리케이션 중심 |
'베어메탈(Bare Metal)'이란 용어는 원래 하드웨어 상에 어떤 소프트웨어도 설치되어 있지 않은 상태를 뜻합니다.
즉, 베어메탈 서버는 가상화를 위한 하이퍼바이저 OS 없이 물리 서버를 그대로 제공하는 것을 말합니다. 따라서 하드웨어에 대한 직접 제어 및 OS 설정까지 가능합니다.
| 하이퍼바이저 | 시스템에서 다수의 운영 체제를 동시에 실행할 수 있게 해주는 논리적 플랫폼 Type 1(Native 또는 Bare-metal) 또는 Type2 (Hosted) |
| 물리적 리소스 공유 | 물리적 리소스 -> 가상 리소스 |
| CPU 리소스 공유 | 가상 환경에서 운영 체제는 시스템의 모든 물리적 CPU중 할당 받은 CPU만을 소유한 것으로 인식 |
| 메모리 리소스 공유 | 가상 환경에서 운영 체제는 시스템의 모든 물리적 메모리중 할당 받은 메모리만을 소유한 것으로 인식 |
| 가상 네트워킹 | 가상 이더넷 어댑터와 가상 스위치는 하이퍼바이저가 소프트웨어적으로 구현하여 제공 |
클라우드란?
| 클라우드 | 쓰는 만큼만 요금을 내고 사용 |
| 클라우드 컴퓨팅 | 인터넷을 통해 IT 리소스를 원할 때 언제든지 사용하고, 사용한 만큼 비용을 지불하는 서비스 |
클라우드 유형
| 퍼블릭 클라우드 | 클라우드 컴퓨팅 서비스를 제공해주는 업체(CSP, Cloud Service Provider)에게 인프라에 필요한 자원들을 대여하여 사용하는 방식 CSP 예 : AWS, Azure, GCP, KT 클라우드, 네이버 클라우드 |
| 프라이빗 클라우드 | 기업이 직접 클라우드 환경을 구축, 이를 기업내부에서 활용, 계열사에 공개 특정 기업, 특정 사용자만 사용하는 방식 서비스 자원과 데이터는 기업의 데이터센터에 저장 |
| 하이브리드 유형 | 기존 On-premise 에 구성되어 있는 인프라와 Public Cloud를 혼용하여 함께 사용하는 방식 온 프레미스(프라이빗 클라우드) + 퍼블릭 클라우드 |
| 멀티 클라우드 | 2개 이상의 서로 다른 클라우드를 함께 사용하는 방식 – AWS + Azure, AWS + KT 하나의 CSP에 종속되지 않기 위해 사용 |
클라우드 컴퓨팅의 이점
| 초기 선 투자 불필요 | 서비스 규모를 예측하고 미리 서버를 구매하고 관리할 필요가 없음 |
| 저렴한 종량제 가격 | 사용한 만큼 지불하는 종량제와 함께 규모의 경제로 인한 지속적인 비용 절감이 가능 |
| 탄력적인 운영 및 확장 가능 | 필요한 용량을 예측할 필요없이 트래픽 만큼만 사용하거나 손쉽게 확장 가능 |
| 속도와 민첩성 | 시장 상황에 빠르게 대응할 수 있는 민첩성을 통해 비즈니스를 혁신 가능 |
| 비즈니스에만 집중 가능 | 차별화된 서비스를 개발할 수 있는 다양하고 많은 실험 시도 가능 |
| 손 쉬운 글로벌 진출 | 빠른 시간내에 손쉽게 글로벌 고객을 위한 서비스를 시작할 수 있습니다. |
| 탄력성, 민첩성, 다양한 도전 | 탄력적인 확장, 인프라 준비를 위해 짧은 시간 소요, 실패 비용낮음 -> 많은 혁신 가 |
온프레미스와 클라우드
| 온프레미스 | 클라우드 |
| 초기 투자비용 수십억 소요 | 초기 투자비용 거의 없음 |
| 혁신을 위한 시도가 자주 일어나지 않음 | 혁신을 위한 시도가 자주 일어남 |
| 실패 비용 높음 | 실패 비용 낮음 |
| 혁신 속도 느려짐 | 혁신 속도 빨라짐 |
2. AWS 기본 서비스(EC2, VPC, EBS, S3)
Amazon EC2(Elastic Compoute Cloud): 가성 서버/머신 서비스
| EC2 서비스 | 가상 서버 서비스, Virtual Machine 재구성이 가능한 컴퓨팅 리소스 쉽게 확장/축소되는 컴퓨팅 용량 ‘고객 업무’ 영역에 따른 다양한 인스턴스 타입 제공 사용한 만큼만 과금 (pay-as-you-go) - 초 |
| EC2 지원 OS | Windows 2003R2/2008/2008R2/2012/2012R2/2016 Amazon Linux Debian Suse CentOS Red Hat Enterprise Linux Ubuntu macOS iOS iPadOS |
| 폭 넓은 컴퓨팅 인스턴스 타입 제공 | 범용(T,M,A) 컴퓨팅 최적화(C) 스토리지/IO 최적화(I,D) GPU 사용(P,G) 메모리 최적화(X,R) |
| 인스턴스 읽는 법 |  |
EC2 구매 옵션
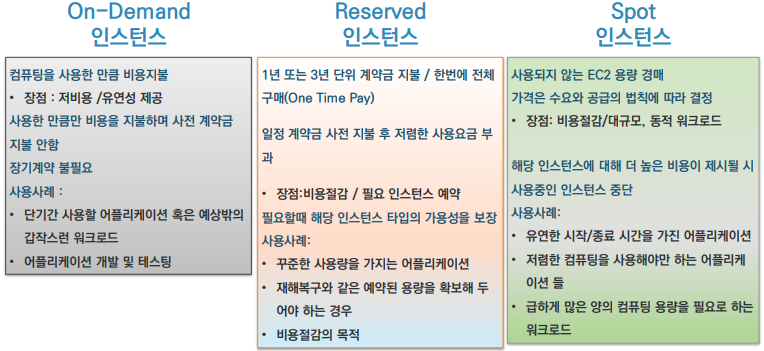
EC2 Security Group
| 보안그룹 규칙 | Name Description Protocol Port range IP address, IP range, Security Group name |
| 특징 | In/Out bound 지정 가능 모든 인터넷 프로토콜 지원 인스턴스 동작 중에도 규칙 변경 가능 |
| 계층적인 보안그룹 | IP Range 대신 어느 SG로부터의 트래픽을 허용할지 지정가능 계층적인 네트워크 구조 생성 가능 |
| EC2 접속 (인증)암호 | 표준 SSH RSA key pair Public/Private Keys Private keys 는 AWS에 저장되지 않음 EC2 key pairs – Linux 최초 로그인시 SSH key pair 생성 Windows - 관리자 암호 불러오기 AWS가 제공하는 초기 OS 접속 방법 높은 보안성 제공 Personalized |
VPC(Virtual Private Cloud) 서비스: 네트워크 서비스
사용자가 정의한 가상의 네트워크 환경, 통신을 위한 기본 네트워크, 보안 강화 목적, 부족한 IP 자원의 효율적인 관리 목적
VPC 생성 과정
| 1 | 2 | 3 | 4 |
| Region, IP대역 결정(CIDR) | 가용영역(AZ)에 Subnet 생성 | Routing 설정 | Traffic 통제 (In/Out) |
| CIDR로 VPC 생성 | CIDR로 Subnet 생성 | 내부 외부 경로 설정 | 네트워크 규칙으로 통제 |
참고: https://ko.rakko.tools/tools/27/
IPv4 / IPv6 CIDR 계산기 | RAKKOTOOLS🔧
IPv4 / IPv6 CIDR 주소를 기반으로 IP 주소 범위를 계산하십시오.서브넷 마스크 범위의 첫 번째 및 마지막 IP 주소, CIDR 표기법의 IP 주소 수, 서브넷 마스크 / 와일드 카드 마스크 (IPv4 CIDR), Ipv6 약자 /
ko.rakko.tools
VCP 생성 과정 1: Region, IP대역 결정
서브넷 마스크(클래스)를 활용해서 IP 대역을 결정하면 단순하게 관리하지만 Network 할당에 자유도가 낮다.
특히 A 클래스 범윙서 쪼금 더 필요할 때 B 클래스 까지 사용해야 되기 때문에 비효율적인 부분이 있다.
CIDR로 할당하면 쫌촘촘하게 관리가 가능해 효율적인 사용이 가능하다.
CIDR 설정하는 방법
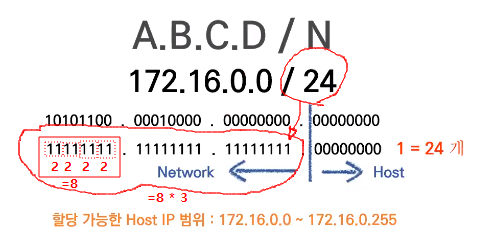
N이 네트워크 할당량
당연하게도 네트워크 할당이 클수록 HOST 개수가 줄어든다.
예시
192.168.0.0/16 일 때 네트워크 주소와 호스트 주소를 구분해보자
16이니까
11111111.11111111.00000000.00000000
-> 1이 있는 범위가 네트워크 ID, 0 부분이 호스트 ID다.
*** ID 와 주소의 범위는 다르다.
내가 강의를 들으면서 자꾸 갸우뚱 했던 부분이였다.
네트워크 ID와 호스트ID가 내 머리속에는 반대로 있기 때문이다.
알고보니 호스트 주소와 네트워크 주소였다.
~~**증~말 헷갈렸기 때문에 극복 하고자 내가 만들어본 문제이다.**~~
이 문제는 에이블스쿨 3기 순제로의 머릿속에서 부터 시작되었으며, 공부만 할라고 하면 자꾸 누가 말을 거는 저주에 걸렸습니다ㅋㅋ. 이 저주를 풀기 위해 주변사람 3명에게 전달하시오. 아우 배고파
| 1번 문제 |
| 192.168.137.1/16 의 네트워크 ID와 호스트 ID를 구분하시오. 192.168.137.1/24 의 네트워크 ID와 호스트 ID를 구분하시오. |
| 2번 문제 |
| 192.168.137.1/16 의 네트워크 범위와 호스트 범위를 구분하시오. 192.168.137.1/24 의 네트워크 범위와 호스트 범위를 구분하시오 |
1번문제 답

2번문제 답

CIDR 의 주소 범위는 IP 서브넷마스크와 확실한 차이를 보여준다.
CIDR 단점
CIDR 숫자를 너무 타이트하게 관리하는 경우, 추후 동일 Network 대역에 IP 부족 현상이 발생할 수 있음
CIDR 은 VPC 생성 이후 변경 불가
VPC CIDR은 16~28bit 사이만 설정 가능
VCP 생성 과정 2: CIDR Subnet 생성
Subnet: VPC 의 IP 대역을 적절한 단위로 분할 사용
목적: 보안

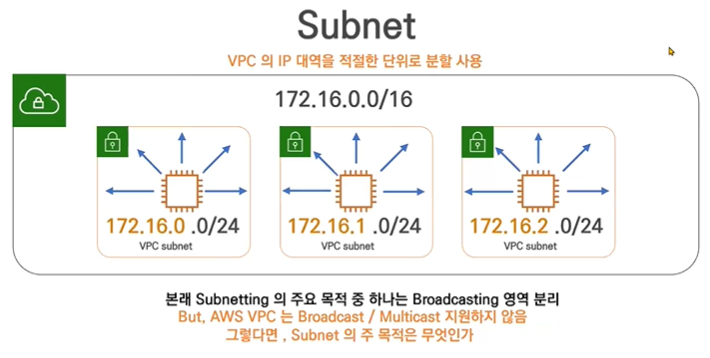
| 특징 | 각 Subnet 도 VPC 와 마찬가지로 CIDR 을 이용해 IP 범위를 지정 |
| 각 Subnet 의 대역은 VPC 의 대역에 존재해야함 | |
| 각 Subnet 의 대역은 중복 불가 | |
| 역할 |
본래 Subnetting 의 주요 목적 중 하나는 Broadcasting 영역 분리 |
| 하지만, AWS VPC 는 Broadcast / Multicast 지원하지 않음 |
|
| 그렇다면 , Subnet 의 주 목적은 무엇인가 | |
| 고려사항 | ubnet 의 CIDR 은 생성 후 변경 불가 |
| Subnet 의 IP 대역 중 예약된 IP 존재 |
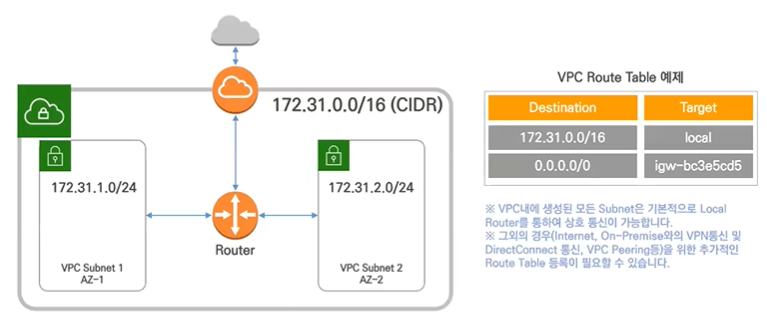
VCP 생성 과정 3: Subnet의 Routing 설정
기본으로 하나 생성됨: 로컬(자기 자신)

VPC 는 기본 외부 통신 단절, 외부 통신 하려면 Internet Gateway 를 통해야만 함
Subnet 별로 경로를 제어 원하는 트래픽만 Subnet 별로 받을 수 있도록 네트워크 레벨에서 격리 시키는 것이 목적
Subnet 의 트래픽 경로 설정 Route 설정을 통해 Subnet 의 통신 방향을 결정할 수 있음
VCP 생성 과정 4: Traffic 통제 (In/Out)
Routing Table 특징
VPC 생성시 자동으로 Main Routing Table 생성
Subnet 은 하나의 Routing Table 과 연결될 수 있음
Main Routing Table 은 삭제 불가
Custom Route Table
AWS Storage Type
| Block Storage | File Storage | Object Storage |
| 사용자의 데이터가 Local Disk 또 는 SAN Storage 상의 Volume 에 Block 단위로 저장 및 Access 하는 스토리지 유형 | 파일 시스템으로 구성된 저장소를 Network 기반 Protocol 을 사용하여 파일 단위로 Access 하는 스토 리지 유형 (NAS) | Encapsulate 된 데이터 및 속성, 메타데이터, 오브젝트 ID 를 저장하 는 가상의 컨테이너. API 기반의 데이터 접근 메타데이터 또는 정책에 기반한 운 영 |
| Amazon EBS (Elastic Block Store) | Amazon EFS, FSx (Elastic File System) | Amazon S3, Glacier (Simple Storage Service) |
Block Storage(HDD/SSD 관리): EBS
| EBS(Elastic Block Store) | AWS 에서 제공하는 Block Storage 서비스 사용이 쉽고 확장 가능한 고성능 블록 스토리지 서비스로서 EC2 용으로 설계 |
| EBS 특징 | EC2 인스턴스를 위한 비 휘발성 블록 스토리지 가상 디스크 = Volume(볼륨) API 기반(명령어 기반) 볼륨 생성, 연결, 삭제 다양한 타입 지원 네트워크를 통한 연결 – 인스턴스 간 연결 및 해제 언제든 가능 – 특수한 경우 제외하고, EBS Volume 은 동시에 하나의 Instance 연결 가능 온라인 변경 – 디스크 추가 및 Scale up |
| EBS 볼륨과 인스턴스는 같은 Availability Zone 에 있는 경우 연결 가능 인스턴스와 볼륨 연결시 데이터 전송 속도가 중요하므로, 동일 네트워크상의 Availability Zone 에 있어야 데이터 처리 속도 보장 |
네트워크를 통한 연결 ?
- 인스턴스 간 연결 및 해제 언제든 가능
- 특수한 경우 제외하고, EBS Volume 은 동시에 하나의 Instance 연결 가능
온라인 변경?
– 디스크 추가 및 Scale up
EBS 볼륨을 다른 AZ 로 이동할 수 있나요?
– Snapshot 생성 후 다른 AZ에 EBS 생성 가능
EBS 볼륨을 다른 Region 으로 이동 할 수 있나요?
– Snapshot 생성 후 다른 Region 으로 Snapshot Copy – 타 Region 으로 복제된 Snapshot 으로 EBS 볼륨 생성
Volume Type
| SSD | HDD |
| 플래시 메모리를 활용한 데이터 저장 방식 | 마그네틱 판에 데이터를 기록하는 방식 |
| 데이터 위치에 따른 성능 차이 없음 | 물리적으로 회전하는 디스크 축(Spindle) 존재 |
| IO 가 매우 빠르고 소비 전력 적음 | 데이터가 어디에 기록되어 있느냐에 따라 속도 차이 발생 |
| HDD 대비 비싸다는 단점 | SSD 대비 성능이 느리고 물리적 충격에 약함 |
| 동일 데이터 저장시, SSD 보다 저렴 | |
| SSD 기반 볼륨: io2, io2 Block Express , io1 , gp3 , gp2 | HDD 기반 볼륨: st1, sc1 |
EBS 를 사용시 물리적으로 무엇을 사용하느냐는 사용자에게 큰 의미는 없음 (클라우드이기 때문)
어떤 Type 을 사용하느냐에 따라 성능과 특성에 따른 차이가 있으므로 확인 필요
Volume Type을 선택할 때 중요 고려 지표
| Size | 데이터 저장 용량 얼만큼의 데이터 저장 필요한지 초기 산정 |
| IOPS | Input / Ouput Per Seconds 초당 데이터 입출력 Count 지표 데이터를 얼마나 빠르게 읽고 쓸 수 있는지에 대한 대표적인 성능 지표 |
| Throughput | 처리량 지표 – 보통 MiB/S 단위로 사용하며, 초당 얼만큼의 데이터를 처리 가능한지에 대한 성능 지표 |
| Cost | 클라우드 사용시 가장 중요하게 고려되야 하는 점이 바로 비용 서비스 요구사항에 따른 충분한 성능과 용량을 준비하되 비용이 낭비되지 않도록 하는 것이 핵심 |
EBS Volume Snapshot
| EBS Volume Snapshot | EBS 볼륨을 특정 시점 기준으로 복사하여 백업하는 기능 볼륨을 그대로 복사해 놓는 방식으로, 스냅샷 생성 속도가 굉장히 빠른 것이 특징 Snapshot 은 추후 EBS 볼륨으로 다시 생성하거나 AMI 로 변환하여 인스턴스를 배포하는데 사용 |
| EBS Volume Snapshot 저장소 | EBS 볼륨 스냅샷은 실제로는 S3 에 저장 이때, 스냅샷은 마지막 스냅샷 이후 변경분만 저장되는 증분식 백업 (incremental) 볼륨의 데이터 변경 부분만 신규 스냅샷에 저장 나머지 부분은 기존 스냅샷을 참조하는 형태 |
| EBS Snapshot 활용(AZ 간 복사) | Snapshot 을 활용하면 EBS 볼륨을 Availability Zone 넘어서 볼륨을 복사할 수 있음 |
| EBS Snapshot 활용(Region 간 복사) | Snapshot 을 다른 Region 으로 복제하면, 동일 Volume 을 Region 단위로 복사하 여 넘기는 것도 가능 |
*AMI(Amazon Machine Image)
인스턴스를 배포 가능한 템플릿.
운영체제(OS) + System 서버 + Application 이 묶여 있는 형태
Object Storage: S3
| 개념 | Simple Storage Service AWS 에서 제공하는 object Storage 서비스 언제 어디서나 원하는 양의 데이터를 저장, 검색할 수 있는 객체 기반 스토리지 서비스 |
| 특징 | Object 스토리지 서비스 웹 서비스 기반 인터페이스 제공 (REST API 기반 데이터 생성 / 수정 / 삭제 ) 고가용성 : 99.9 (x11) % 내구성 제공 무제한 용량 제공 • 초기 저장 용량 확보 불필요. 사용한 만큼 과금 강력한 보안 기능 (IAM 과 연계된 권한 관리) Versioning 기능 제공 주요 용도 – Backup & Archiving – Big Data Analytics – Cloud-native Application Data – Static Website Hosting |
| S3 Bucket | • Object 를 저장하는 컨테이너 (저장소 역할) • Object 는 반드시 하나의 Bucket 에 속해야 함 • Bucket 에 저장할 수 있는 Object 는 무제한 • AWS Account 당 최대 Bucket 100 개까지 가능 |
| S3 Object, Key | Object (객체) 는 S3 에 저장되는 기본 개체 Object 하나의 최대 크기는 5TB Object 는 데이터와 메타데이터로 구성되어 있음 – 메타데이터 : Object 를 설명하는 이름-값 페어 – 기본 메타데이터 및 Content-Type 같은 HTTP 메타데이터 포함 Key(키) 및 Version ID (Versioning 활성화한 경우) 를 통해 버킷 내 고유 식별 • Bucket 내 Object 에 대한 고유한 식별자 "Bucket + Key + Version ID" 조합은 각 Object 를 고유하기 식별 가능 S3 내 모든 Object 는 웹 서비스 endpoint 를 갖게 됨 https://example-bucket.s3.us-east1.amazoneaws.com/photos/puppy.jpg – Bucket: example-bucket – Key: /photos/puppy.jpg |
| S3 특징 - Region | Bucket 생성시, 해당 Bucket 을 저장할 Region 을 선택 가능 지연 시간 최소, 비용, 규정 요구 사항 준수 등 다양한 조건에 따라 Region 을 선택 해당 Bucket에 생성된 Object 는 Bucket 의 Region 에 따라 저장됨 독특하게도, 다른 리소스들과는 다르게 S3 는 AWS Console 에서 모든 Region 에 생성된 Bucket 이 다 같이 보임 |
| S3 특징 - Versioning | 동일 Bucket 내 여러 개의 Object 변형을 보존하는 방법. Key 는 동일하지만, Version ID 가 다른 두개의 Object 보유. Bucket Versioning 사용시, 모든 버전의 Object 를 보존, 복원 가능. 변경 사항을 계속 저장하는 것이기 때문에 S3 저장 비용 추가 지불 |
{kind=link}
s3 스토리지 클래스
| S3 Standard | 자주 액세스 하는 데이터를 위한 높은 내구성, 가용성, 성능을 갖춘 스토리지 클래스. 여러 Availability Zone 에 분산 중복 저장, 99.9(x11) % 의 내구성, 99.99% 의 가용성 보장 클라우드 웹 어플리케이션, 컨텐츠 배포, 빅데이터 분석 등 다양한 케이스 적합 |
| S3 Standard-Infrequent Access (Standard-IA) |
자주 액세스하지 않는 데이터이지만, 필요할때 빠르게 액세스해야 하는 데이터에 적합한 클래스. 데이터 내구성과 고가용성은 Standard 와 동일하나, 데이터 액세스에 소요되는 지연속도가 Standard 에 비해 느림. GB 당 검색 요금 추가 적용. 장기 스토리지, 백업 및 재해 복구 파일 저장에 적합 |
| S3 One Zone Infrequent Access (S3 One Zone-IA) |
단일 Availability Zone 에 데이터를 중복 저장하도록 설계된 스토리지 클래스. (Standard-IA 대비 20% 낮은 비용) 온프레미스 데이터 또는 쉽게 다시 생성 가능한 데이터의 보조 백업 복사본 용도로 적합 |
| S3 Intelligent-Tiering | 데이터 액세스 패턴을 지속적으로 확인 및 분석하여 자동으로 가장 효율적인 스토리지 클래스로 이동하 여 주는 클래스. 약간의 월별 객체 모니터링 및 자동화 요금 지불 |
| S3 Glacier Instant Retrieval | 데이터에 거의 액세스 하지 않으면서, 밀리초 단위 검색이 필요한 장기 데이터 저장 용도 클래스. 분기당 1회 액세스한다고 가정, Standard-IA 대비 최대 68% 저렴. 의료 이미지, 뉴스 미디어 아카이브 용도에 적합. S3 수명 주기 정책을 사용하여 데이터 전송 가능 |
| S3 Glacier Flexible Retrieval | 연간 1~2회 액세스하고 비동기식으로 검색되는 아카이브 데이터 저장 용도 클래스. Glacier Instant Retrieval 대비 최대 10% 저렴. 즉각적인 액세스 없이 백업 또는 재해 복구 와 같은 대규모 데이터 집합 저장 용도로 적합 |
| S3 Glacier Deep Archive | S3 중 가장 저렴한 비용의 스토리지 클래스. 최소 7~10년 이상 데이터를 저장하는 고객 (금융 서비스, 의료, 공공 부문과 같은 엄격한 규제 산업) 을 위해 설계. |
| S3 on Outposts | 온프레미스 Outpost 환경에서 제공되는 객체 스토리지 클래스. 로컬 저장 요구사항이 있는 워크로드에 적합 데이터를 온프레미스 어플리케이션과 가까이 저장해서 까다로운 성능 요구 사항을 목표로 함. |
3. AWS 고가용성 구현(Region, AZ, ELB, ASG)
| 가용성 | 서비스 가용성이라고도 표현 워크로드를 사용할 수 있는 시간의 비율 |
| 고가용성 | High Availability 높은 가용성 지속적으로 구현한 시스템이 정상적으로 운영이 되는 성질 장애 또는 고장이 나더라도 복구를 해서 서비스를 지속할 수 있는 능력 |
고가용성: Region / Availability Zone
AWS는 Region과 Availability Zone으로 이루어져 있음
| 개념 | 설명 |
| Region | 전 세계에서 데이터센터를 클러스터링하는 물리적 위치 어떤 지역으로 서비스하느냐에 따라 지리적으로 가까운 Region 선택 |
| Region Code | Region 구분 Code 존재 (ex. us-east-1, ap-northeast-2 ) AWS 는 Region 단위로 별도 서비스되는 형태 Resource 는 Region 내 Availability Zone 단위로 배포 |
| Availability Zone | 물리적으로 분리된 데이터 센터( 서울 리전, 도쿄 리전 등등) Region 내 물리적으로 분리된 전력 네트워킹 장치가 분리된 영역 보통 AZ 별 데이터센터 분리된 구조 (AZ 사이는 물리적으로 100KM 이내 존재) |
| AZ 간 구성 |  Region 은 보통 2~3개 Availability Zone 으로 구성 동일 Region 내 AZ 는 전용 광 네트워크로 구성되어 매우 낮은 지연 속도와 높은 처리량 보장 AZ간 모든 데이터 트래픽은 기본 암호화 |
| AZ 분산 배치 |  만약 동일 Availability Zone 내 모든 인스턴스를 배치하는 경우, 해당 AZ 장애 발생시, 본인이 구축한 서비스도 장애로 이어질 수 있음. 동일 역할을 수행하는 인스턴스의 경우, AZ 를 분산 배치하여 서비스 가용성을 높이는 것이 좋음 |
| AZ와 VPC | 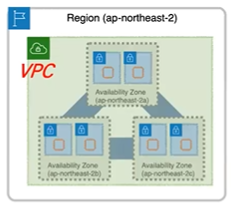 Region - VPC 와 맵핑 Availability Zone - Subnet 과 맵핑 Instance 생성시 VPC 와 Subnet 을 선택하여 배포 |
| VPC 구성 예: Public Subnet & Private Subnet |
 VPC 구성 시, 목적에 따라 Subnet 을 구분하여 생성 Public Subnet : 외부 통신용 – Private Subnet : Public 과 Private 간 연동용 외부 통신시 NAT Gateway 를 통한 단방향 허용 – Private Subnet 2 : 외부 통신 X |
| VPC 구성 예: AZ별 Subnet 구성 |
 각각의 Subnet 을 AZ 수 만큼 생성 Total Subnet 수 = AZ Count X 용도별 Subnet 인스턴스 생성시 각 사용처에 맞는 Subnet 을 선택 후, AZ 별로 분산 구성 |
| VPC 구성 예: AZ 장애 발생 시 |
Availability Zone 장애시, 동일 용도의 인스턴스 및 서비스 Set가 다른 Availbility Zone 에 구성되어 있으므로, 가용성을 높일 수 있음 |
ELB(Elastic Load Balancer)
*Load Balancer: 인입되는 트래픽을 특정 알고리즘 기반으로 다수의 서버로 분산 시켜주는 장비
| ELB 특징 | Region 내 인스턴스 및 다양한 서비스로 트래픽 분배 서비스 다수의 Availability Zone 으로 트래픽 분배 HTTP/S 웹 기반 트래픽, TCP/S 프로토콜 기반 Backend 인스턴스에 대한 Health Check 수행 고가용성 기반 L4/L7 서비스 Availability Zone 분산 및 Traffic 증가 시 자동 Scale-out 기능 지원 |
| ELB 4 Type | Application Load Balancer (ALB): HTTP/HTTP(S) 트래픽 처리 특화된 L7 로드밸런서 Network Load Balancer (NLB): TCP/UDP 처리 특화 고정 IP 주소 사용 가능한 로드밸런서 Gateway Load Balancer (GLB): Third-party 가상 어플라이언스 관리를 위한 Gateway 용 로드밸런서 Class Load Balancer (CLB): EC2 Classic 네트워크용 구 로드밸런서 사용 권장 하지 않음 (EC2 Classic 네트워크는 2022.8.15 종료예정) |
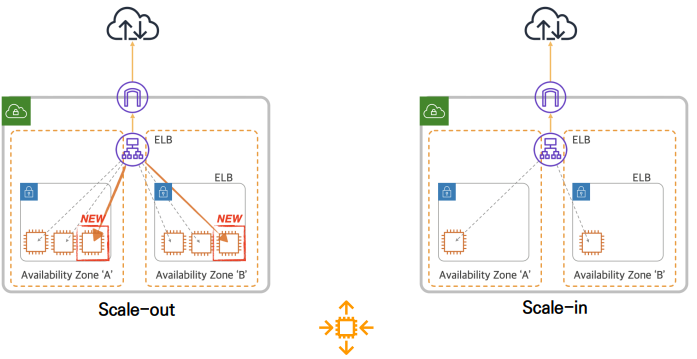
| Scale-out |  트래픽 증가시, 서비스에 투입되는 서버를 증설하여 각 서버가 처리하는 부하를 낮추는 방식 Web based 서비스의 경우 많이 사용하는 구성으로 Session 이나 Data 처리 영역 없이 Stateless 한 서버에서 주로 사용 |
| Scale-in | 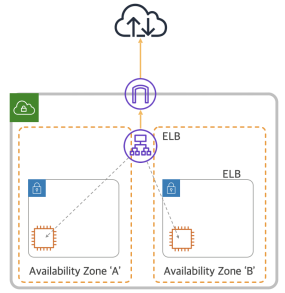 트래픽 감소 시, 배포된 서버를 제거하는 방식 낭비되는 리소스를 줄임으로 비용 최적화 목적 |
| ELB 알고리즘 |  어떤 규칙으로 트래픽을 인스턴스로 분배할 것인가 – Roud Robin – Hashing – Weighted RR – Least Connection – Weighted LC |
AWS NLB, ALB
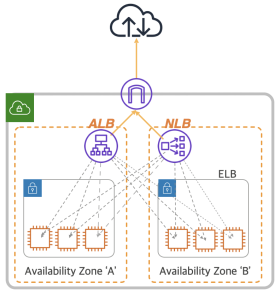
| NLB(Network Load Balancer) | L4 Load Balancer, TCP/UDP |
| ALB(Application Load Balancer) | L7 Load Balancer, HTTP/HTTPS |
ELB 헬스체크 기능
: 주기적으로 서버가 정상 상태인지 확인하고 정상상태가 아닌 서버에게는 트래픽을 전달 하지 않게 하는 기능
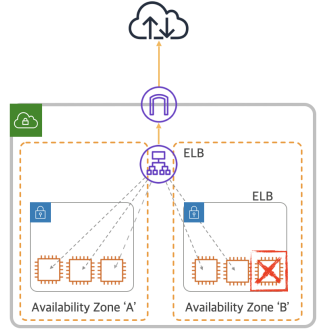
| NLB | TCP/UDP Port Alive Check |
| ALB | URL 기반 응답 체크(200) |
ELB AZ 분산배치
활성화된 Availbility Zone 에는 로드 밸런서 노드가 자동으로 생성되어 배치
기본적으로 해당 AZ에 배치된 타겟(인스턴스)는 해당 AZ의 로드밸런서 노드가 트래픽 을 처리
*ELB 생성시 Availability Zone 활성화 필요
Cross-Zone Load Balancing
교차 영역 로드 밸런싱이 활성화 되면, 로드 밸런서가 위치한 Availability Zone 과 상 관 없이 타겟 Availability Zone 에 있는 모든 인스턴스에 트래픽 라우팅 가능
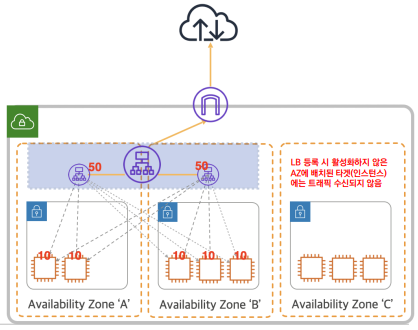
– Application LoadBalancer (ALB) 는 Cross-Zone LB 가 기본 활성화
– Network LoadBalancer (NLB) 는 기본 비활성화
Cross-Zone Load Balancing 비활성화
교차 영역 로드 밸런싱이 비활성화 상태이면, 로드 밸런서 노드가 위치한 Availability Zone 에 상주하는 타겟 인스턴스에게만 라우팅 가능
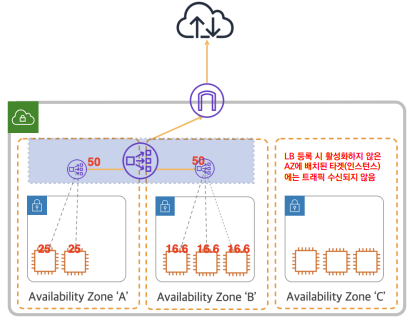
Availability Zone 에 위치한 인스턴스 마다 균일한 부하 분산이 어려움
Auto Scaling Group
Scaling 을 자동으로: Auto Scaling
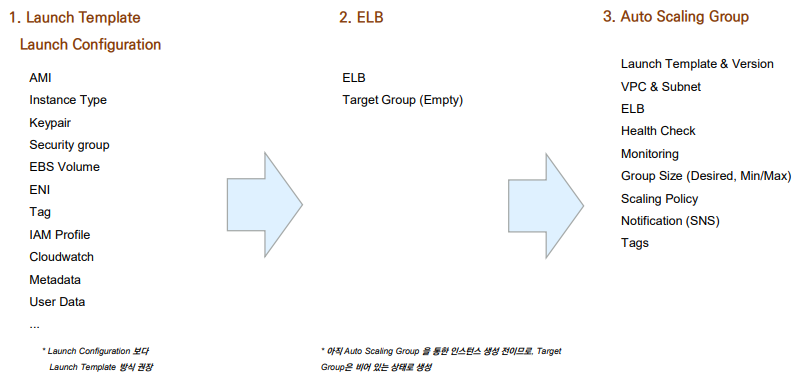
Auto Scaling Group 설정
1. Auto Scaling 은 무엇을 대상으로 할 것인가?
– Launch Template : AMI, Instance Type 등 Instance 에 대한 정의
2. 자동 설정 정책을 어떻게 설정할 것인가?
– Auto Scaling Group : Desired Capacity, Min/Max Size, Target Group 등 자동 확 장에 대한 정의
Launch Template
인스턴스를 배포하기 위한 정보들의 묶음
AMI, Instance Type, Keypair, Security Group, Network 와 같은 기본 정보
IAM Role, Userdata, Tags, 등 추가 정보를 미리 Template 으로 정의 가능
사용자는 해당 Template 을 그대로 인스턴스로 배포 하는데 사용
Auto Scaling Group 구성 단계
'KT AIVLE School 3기 > AIVLER 활동' 카테고리의 다른 글
| [AIVLE_AI] 가상화 클라우드 3일차 (0) | 2023.05.05 |
|---|---|
| [AIVLE_AI] 가상화 클라우드 2일차 (0) | 2023.05.04 |
| [AIVLE] AI_IT인프라 (0) | 2023.04.24 |
| [Colab Trouble Shooting] [E941] Can't find model 'en'. It looks like you're trying to load a model from a shortcut, which is obsolete as of spaCy v3.0. To load the model, use its full name instead: nlp = spacy.load("en_core_web_sm") (0) | 2023.04.10 |
| [AIVLE_AI] 웹 크롤링 (0) | 2023.03.16 |