출처: https://wikidocs.net/book/1
점프 투 파이썬
이 책은 파이썬이란 언어를 처음 접해보는 독자들과 프로그래밍을 한 번도 해 본적이 없는 사람들을 대상으로 한다. 프로그래밍을 할 때 사용되는 전문적인 용어들을 알기 쉽게 풀어서 …
wikidocs.net
숫자형
# 실수형
a = 1.2
a = -3.45
# 실수형 소수점 표현 방식
a = 4.24E10 #4.24*10^10
a = 4.24e-10 # 4.24*10^-10
# 8진수
a= 0o177
# 16진수
a = 0x8ff
a = 0xABC# 사칙연산
a = 3
b = 4
a + b7
a-b-1
a*b12
a/b0.75
# x의 y제곱을 나타내는 **연산자
a = 3
b = 4
a **b81
문자열 자료형
# 큰 따옴표(")로 양쪽 둘러싸기
"Hello World"
# 작은 따옴표(')로 양쪽 둘러싸기
'Python is fun'
# 큰 따옴표 3개를 연속(""")으로 써서 양쪽 둘러싸기
"""Life is too short, you need python"""
# 작은 따옴표 3개를 연속으로 써서 양쪽 둘러싸기
'''Life is too short, you need python'''# 문자열 안에 작은 따옴표나 큰 따옴표를 포함시키고 싶을 때
# 문자열에 작은 따옴표(') 포함시키기
food = "Python's favorite food is perl"
food# 작은 따옴표로 문자열 둘러싸기
food = 'Python's favorite food is perl'
food-에러 발생
# 문자열 에 큰 따옴표(") 포함시키기
say = '"Python is very easy." he says'
say"Python is very easy." he says
# 백슬래시(\)를 사용해서 작은 따옴표(')와 큰 따옴표(") 문자열에 포함시키기
food = 'Python\'s favorite food is perl'
say = "\"Python is very easy. \" he says"
food
say"Python is very easy." he says
# 여러 줄인 문자열을 변수에 대입하고 싶을 때
multiline = "Life is too short\nYou need python"
multilineLife is too short
You need python
multiline='''
Life is stoo short
You need python
'''
print(multiline)Life is stoo short You need python
이스케이프 코드

# 문자열 더해서 연결해기(Concatenation)
head = "Python"
tail = " is fun!"
head + tailPython is fun!
# 문자열 곱하기
a = "python"
a * 2pythonpython
# 문자열 곱하기 응용
# multistring.py
print("="*50)
print("My Program")
print("="*50)==================================================
My Program
==================================================
# 문자열 길이 구하기
a = "Life is too short"
len(a)17
a = "Life is too short, You need Python"
a[3]e
a[-1]n
# 문자열 슬라이싱
a = "Life is too short, You need Python"
b = a[0]+a[1]+a[2]+a[3]
bLife
c = a[0:4]
cLife
c = a[0:5]
cLife
a[0:2]Li
a[12:17]short
# 슬라이싱으로 문자열 나누기
a = "20100331Rainy"
year = a[:4]
date = a[:8]
weather = a[8:]
date20100331
weatherRainy
year2010
# 예제: Pithon 이라는 문자열을 Python으로 바꾸려면?
a = "Pithon"
a[1]i
#문자열의 요솟값은 바꿀 수 있는 값이 아니기 때문이다(문자열 자료형은 그 요솟값을 변경할 수 없다. 그래서 immutable한 자료형이라고도 부른다).
a[1] = yNameError: name 'y' is not defined
문자열 포메팅
# 숫자 바로 대입
"I eat %d apples." % 3I eat 3 apples.
# 문자열 바로 대입
"I eat %s apples" %"five"I eat five apples
#숫자 값을 나타내는 변수로 대입
number = 3
"I eat %d apples." %numberI eat 3 apples.
# 2개 이상의 값 넣기
number = 10
day = "three"
"I ate %d apples. so i was sick for %s days" %(number, day)I ate 10 apples. so i was sick for three days
문자열 포멧 코드
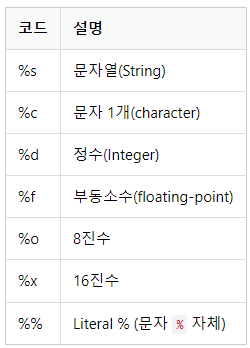
# %s 포멧 코드, 어떤 형태의 값이든 변환해 넣을 수 있다.
"I have %s apples" %3I have 3 apples
"rate is %s" %3.234rate is 3.234
#포매팅 연산자 %d와 %를 같이 쓸 때는 %%를 쓴다
"Error is %d%%." %96Error is 96%.
"Error is %s%%." %0.96Error is 0.96%.
# 포멧 코드와 숫자 함께 사용하기
# 정렬과 공백
"%10s" % "hi"hi
"%-10s" % "hi"hi
# 소수점 표현하기
"%0.4f" %3.121342343.1213
"%10.4f" %3.121342343.1213
# format 함수를 사용한 포매팅
# 숫자 바로 대입하기
"I eat {0} apples".format(3)I eat 3 apples
# 문자열열 바로 대입하기
"I eat {0} apples".format("five")I eat five apples
# 2개 이상의 값 넣기
number = 10
day = "three"
"I ate {0} apples. so I was sick for {1} days.".format(number, day)I ate 10 apples. so I was sick for three days.
# 이름으로 넣기
"I ate {number} apples. so I was sick for {day} days.".format(number=10, day=3)I ate 10 apples. so I was sick for 3 days.
# 인덱스와 이름을 혼용해서 넣기
"I ate {0} apples. so I was sick for {day} days".format(10, day=3)I ate 10 apples. so I was sick for 3 days
# 왼쪽 정렬
"{0:<10}".format("hi")hi
#오른쪽 정렬
"{0:>10}".format("hi")hi
#가운데 정렬
"{0:^10}".format("hi")hi
# 공백 채우기
"{0:=^10}".format("hi")====hi====
"{0:!<10}".format("hi")hi!!!!!!!!
"{0:!>10}".format("hi")!!!!!!!!hi
#소수점 표현하기
y = 3.42134234
"{0:0.4f}".format(y)3.4213
"{0:10.4f}".format(y)3.4213
# { 또는 } 문자 표현하기
"{{and}}".format(){and}
# f 문자열 포메팅
name = '홍길동'
age = 30
f'나의 이름은 {name}입니다. 나이는 {age} 입니다.'나의 이름은 홍길동입니다. 나이는 30 입니다.
age = 30
f' 나는 내년이면 {age+1}살이 된다.'나는 내년이면 31살이 된다.
d = {'name':'홍길동', 'age':30}
f'나의 이름은 {d["name"]}입니다. 나이는 {d["age"]}입니다.'나의 이름은 홍길동입니다. 나이는 30입니다.
# 정렬
f'{"hi":<10}' # 왼쪽 정렬hi
f'{"hi":>10}' # 오른쪽 정렬hi
f'{"hi":^10}' # 가운데 정렬hi
# 공백 채우기
f'{"hi":=^10}' # 가운데 정렬하고 = 문자로 공백 채우기====hi====
f'{"hi":!<10}' # 왼쪽 정렬하고 ! 문자로 공백 채우기hi!!!!!!!!
# 소수점 표현하기
y = 3.42134234
f'{y:0.4f}'3.4213
f'{y:10.4f}'3.4213
# 문자열에서 {} 표시하기
f'{{and}}'{and}
문자열 관련 함수
# 문자 개수 세기(count)
a = "hobby"
a.count('b')2
# 위치 알려주기1(find)
a = "Python is the best choice"
a.find('b')14
a.find('k')-1
# 위치 알려주기2(index)
a = "Life is too short"
a.index('t')8
a.index('k')ValueError: substring not found
# 문자열 삽입(join)
",".join('abcd')a,b,c,d
",".join(['a','b','c','d'])a,b,c,d
# 소문자를 대문자로 바꾸기(upper)
a = "hi"
a.upper()HI
# 대문자를 소문자로 바꾸기(lower)
a = "HI"
a.lower()hi
# 왼쪽 공백 지우기 (lstrip)
a = " hi "
a.lstrip()hi
# 오른쪽 공백 지우기 (rstrip)
a.rstrip()hi
# 양쪽 공백 지우기(strip)
a.strip()hi
# 문자열 바꾸기(replace)
a = "Life is too short"
a.replace("Life", "Your leg")Your leg is too short
# 문자열 나누기(split)
a.split()['Life', 'is', 'too', 'short']
b = "a:b:c:d"
b.split(':')['a', 'b', 'c', 'd']
리스트 자료형
# 리스트란?: 대괄호로 감싸주고, 요소값은 쉼표로 구분
# 리스트 안에는 어떠한 자료형도 포함시킬 수 있다.
odd = [1,3,5,7,9]
odd[1, 3, 5, 7, 9]
# 리스트의 인덱싱
a = [1,2,3]
a[1, 2, 3]
a[0] + a[1]3
a[-1]3
a = [1, 2, 3, ['a','b','c']]a[0]1
a[-1]['a', 'b', 'c']
a[-1][1]b
# 삼중 리스트에서 인덱싱하기
a = [1,2,['a','b', ['Life', 'is']]]a[2][2][0]Life
# 슬라이싱: 나눈다
a = "12345"
a[0:2]12
a[:2]12
a[2:]345
# 중첩된 리스트에서 슬라이싱 하기
a = [1,2,3,['a','b','c'],4,5]
a[2:5][3, ['a', 'b', 'c'], 4]
a[3][:2]['a', 'b']
- 리스트 연산하기
# 리스트 더하기
a = [1,2,3]
b = [4,5,6]
a + b[1, 2, 3, 4, 5, 6]
# 리스트 반복하기(*)
a = [1,2,3]
a * 3[1, 2, 3, 1, 2, 3, 1, 2, 3]
# 리스트 길이 구하기
a = [1,2,3]
len(a)3
- 리스트 수정과 삭제
# 리스트에서 값 수정하기
a = [1,2,3]
a[2] = 4
a[1, 2, 4]
# del 함수 사용해 리스트 요소 삭제하기
a = [1,2,3]
del a[1]
a[1, 3]
# 슬라이싱 기법으로 여러개 삭제
a = [1,2,3,4,5]
del a[2:]
a[1, 2]
- 리스트 관련 함수
- 리스트 변수 이름 뒤에 '.'를 붙여서 여러 가지 리스트 관련 함수를 사용할 수 있다.
# 리스트에 요소 추가(append)
a = [1,2,3]
a.append(4)
a[1, 2, 3, 4]
a.append([5,6])
a[1, 2, 3, 4, [5, 6]]
# 리스트 정렬(sort)
a = [1,4,3,2]
a.sort()
a[1, 2, 3, 4]
# 리스트 알파벳 순서로 정렬
a = ['a','d','c','b']
a.sort()
a['a', 'b', 'c', 'd']
# 리스트 뒤집기 (reverse)
a. reverse()
a['d', 'c', 'b', 'a']
# 인덱스 반환(index)
a = [1,2,3]
a.index(3), a.index(2)(2, 1)
# 리스트에 요소 삽입
a = [1,2,3]
a.insert(0,4)
a[4, 1, 2, 3]
# 리스트에 요소 제거
a.remove(4)
a[1, 2, 3]
# 요소 끄집어 내기 (pop): 리스트의 맨 마지막 요소 리턴 후 삭제
a = [1,2,3]
a.pop()
a[1, 2]
a.pop(1)2
a[1]
# 리스트에 포함된 요소 x의 개수 세기(count)
a = [1,2,3,1]
a.count(1)2
# 리스트 확장(extend): extend(x)에서 x에는 리스트만 올 수 있으며 원래의 a 리스트에 x 리스트를 더하게 된다.
a.extend([4,5])
a[1, 2, 3, 1, 4, 5]
#a.extend([4, 5])는 a += [4, 5]와 동일하다.a = [1,2,3]
a += [6,7]
a[1, 2, 3, 1, 4, 5, 6, 7]
튜플 자료형
-
리스트는 [ ]으로 둘러싸지만 튜플은 ( )으로 둘러싼다.
-
리스트는 요소 값의 생성, 삭제, 수정이 가능하지만 튜플은 요소 값을 바꿀 수 없다.
# 튜플 요솟솟값 삭제, del 안된다.
t1 = (1,2,'a','b')
del t1[0]# 튜플 요솟값 변경, 안된다.
t1[0] = 'c'TypeError: 'tuple' object does not support item assignment
- 튜플 다루기
# 인덱싱 하기
t1[0]1
t1[3]b
# 슬라이싱 하기
t1 = (1,2,'a','b')
t1[1:]# 튜플 더하기
t1 = (1,2,'a','b')
t2 = (3,4)
t3 = t1 + t2
t3# 튜플 곱하기
t3 = t2*3
t3(3, 4, 3, 4, 3, 4)
# 튜플 길이 구하기
len(t1)딕셔너리 자료형
- 대응 관계, 연관 배열(Associative array) 또는 해시(Hash)
- 리스트나 튜플처럼 순차적으로(sequential) 해당 요솟값을 구하지 않고 Key를 통해 Value를 얻는다
# 딕셔러니 기본 모습
dic = {'Key1':'Value1', 'Key2':'Value2', 'Key3':'Value3'}# 예제를 통한 딕셔너리
dic = {'name':'pey', 'phone':'010-1234-5678', 'birth':'1212'}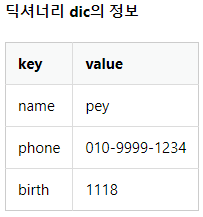
# Key로 정수값 1, Value로 문자열 'hi'
a = {1:'hi'}a[1]hi
# Value에 리스트도 넣을 수 있다.
a = {'a':[1,2,3]}a['a'][1, 2, 3]
- 딕셔너리 쌍 추가, 삭제
a = {1:'a'}
a[2] = 'b'
a{1: 'a', 2: 'b'}
a['name'] = 'pey'
aa[3] = {1,2,3}
a{1: 'a', 2: 'b', 'name': 'pey', 3: {1, 2, 3}}
# 딕셔너리 요소 삭제하기
del a[1]
a{2: 'b', 'name': 'pey', 3: {1, 2, 3}}
- 딕셔너리르 사용하는 방법
# 딕셔너리에 Key 사용해 Value 얻기
grade = {'pey':10, 'julliet':99}
grade['pey']- 딕셔너리 주의사항
- Key는 고유한 값이므로 중복되는 Key 값을 설정해 놓으면 하나를 제외한 나머지 것들이 모두 무시
a{1:'a', 1:'b'}
a[1]SyntaxError: invalid syntax
- 딕셔너리 관련 함수들
# Key 리스트 만들기
a = {'name':'pey', 'phone':'010-1234-5678', 'birth':'1118'}
a.keys()dict_keys(['name', 'phone', 'birth'])
for k in a.keys():
print(k)name
phone
birth
for k in a.values():
print(k)pey
010-1234-5678
1118
# dict_keys 객체를 리스트로 변환
list(a.keys())['name', 'phone', 'birth']
# dict_vlaues 객체를 리스트로 변환
list(a.values())# Key, Value 쌍 얻기(items)
a.items()dict_items([('name', 'pey'), ('phone', '010-1234-5678'), ('birth', '1118')])
#Key: Value 쌍 모두 지우기(clear)
a.clear()
a{}
# Key로 Value얻기(get)
# a.get('name')은 a['name']을 사용했을 때와 동일한 결괏값을 리턴
a = {'name':'pey', 'phone':'010-9999-1234', 'birth': '1118'}
a.get('name'), a.get('phone')# 딕셔너리 안에 찾으려는 Key가 없을 경우 미리 정해 둔 디폴트 값을 대신 가져오게 하고 싶을 때
a.get('nokey', 'hello_sooonzero')hello_sooonzero
#해당 Key가 딕셔너리 안에 있는지 조사하기(in)
a = {'name':'pey', 'phone':'010-9999-1234', 'birth': '1118'}
'name' in aTrue
'email' in a집합 자료형
- 집합 자료형은 set 키워드를 사용해 만들 수 있다.
- 중복을 허용하지 않는다.
- 순서가 없다(Unordered).
s1 = set([1,2,3])
s1s2 = set("Hello")
s2# 집합 자료형을을 인덱싱으로 값을 얻기
s1 = set([1,2,3])
l1 = list(s1)
l1[0]- 교집합, 합집합, 차집합 구하기
- set 자료형을 정말 유용하게 사용하는 경우는 교집합, 합집합, 차집합을 구할 때이다.
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])# 교집합
s1 & s2{4, 5, 6}
# 차집합
s1 - s2{1, 2, 3}
# 합집합
s1 | s2- 집합 자료형 관련 함수들
# 갑 1개 추가하기(add)
s1 = set([1,2,3])
s1.add(4)
s1{1, 2, 3, 4}
# 값 여러개 추가하기(update)
s1.update([5,6,7])
s1{1, 2, 3, 4, 5, 6, 7}
# 특정 값 제거하기(remove)
s1.remove(2)
s1불 자료형
- True - 참
- False - 거짓
a = True
b = Falsetype(a)bool
type(b)bool
1 == 1True
2>1True
1>2- 자료형의 참과 거짓
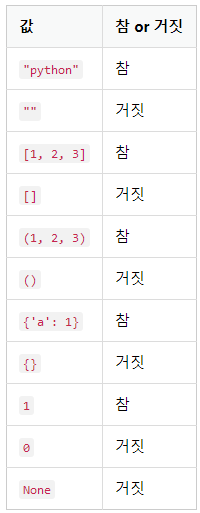
a = [1, 2, 3, 4]
while a:
print(a.pop())4
3
2
1
- 불 연산
bool('python')True
bool('')변수: 자료형의 값을 저장하는 공간
- 변수 이름 = 변수에 저장할 값
# 리스트 복사
a = [1,2,3]
b = aid(a)id(b)a is bTrue
a[1] = 4
b
- b 변수를 생성할 때 a 변수의 값을 가져오면서 a와는 다른 주소를 가리키도록
#[:] 이용: 리스트 전체를 가리키는 [:]을 사용해서 복사
a = [1,2,3]
b = a[:]
a[1] = 4
ab# copy 모듈 이용
from copy import copy
a = [1,2,3]
b = copy(a)b is a- 변수를 만드는 여러 가지 방법
#튜플로 a, b에 값을 대입
a, b = ('python', 'life')#리스트로 변수 만들기
(a,b) = ['python', 'life']#여러 개의 변수에 같은 값을 대입
a = b = 'python'a = 3
b = 5
a, b = b, aa5
b'공부 > Python' 카테고리의 다른 글
| [Python] swap (0) | 2024.04.17 |
|---|---|
| [Python] for-else while-else (0) | 2024.04.16 |
| [점프 투 파이썬 ] 05장 클래스, 모듈 패키지, 예외처리, 내장함수, 라이브러리 (0) | 2023.04.09 |
| [점프 투 파이썬 ] 04장 입력과 출력 (0) | 2023.04.09 |
| [점프 투 파이썬 ] 03장 제어문 (0) | 2023.04.08 |